袗褉褏懈褌械泻褌褍褉邪 懈 褋褌褉褍泻褌褍褉邪 袦袩 (袥械泻褑懈褟)
袩袥袗袧 袥袝袣笑袠袠
1. 孝懈锌褘 泻芯屑邪薪写 屑懈泻褉芯锌褉芯褑械褋褋芯褉芯胁
2. 小褌褉褍泻褌褍褉薪褘泄 锌邪褉邪谢谢械谢懈蟹屑 屑懈泻褉芯锌褉芯褑械褋褋芯褉芯胁
1. 孝懈锌褘 泻芯屑邪薪写 屑懈泻褉芯锌褉芯褑械褋褋芯褉芯胁
袙 褏芯写械
褝胁芯谢褞褑懈芯薪薪芯谐芯 褉邪蟹胁懈褌懈褟 邪褉褏懈褌械泻褌褍褉 锌褉芯褑械褋褋芯褉芯胁 胁 褋芯褋褌邪胁 褋懈褋褌械屑褘 泻芯屑邪薪写 胁胁芯写懈谢懈褋褜
懈, 胁 褋懈谢褍 锌褉械械屑褋褌胁械薪薪芯褋褌懈 锌褉芯谐褉邪屑屑薪芯谐芯 芯斜械褋锌械褔械薪懈褟, 蟹邪泻褉械锌谢褟谢懈褋褜 褋谢芯卸薪褘械
泻芯屑邪薪写褘, 泻芯褌芯褉褘械 锌芯 屑薪械薪懈褞 褉邪蟹褉邪斜芯褌褔懈泻芯胁
褋芯芯褌胁械褌褋褌胁芯胁邪谢懈 褉械褕邪械屑褘屑 蟹邪写邪褔邪屑. 袦械褉芯泄 褝褌芯谐芯 褋芯芯褌胁械褌褋褌胁懈褟 褔邪褖械 胁褋械谐芯 斜褘谢 芯斜褗械屑
写胁芯懈褔薪芯谐芯 泻芯写邪 锌褉芯谐褉邪屑屑褘, 褌邪泻 泻邪泻 屑懈薪懈屑懈蟹邪褑懈褟 写谢懈薪褘 锌褉芯谐褉邪屑屑褘 斜褘谢邪 褉邪胁薪芯蟹薪邪褔薪邪
屑懈薪懈屑懈蟹邪褑懈懈 胁褉械屑械薪懈 懈褋锌芯谢薪械薪懈褟. 袣芯屑邪薪写褘 斜褘胁邪褞褌 褉邪蟹薪褘褏 褌懈锌芯胁:
"褉械谐懈褋褌褉, 褉械谐懈褋褌褉 -> 褉械谐懈褋褌褉", "锌邪屑褟褌褜, 锌邪屑褟褌褜 ->
锌邪屑褟褌褜", "褉械谐懈褋褌褉 -> 锌邪屑褟褌褜" 懈 写褉. 小谢芯卸薪褘械 泻芯屑邪薪写褘
屑芯写懈褎懈褑懈褉褍褞褌 褋芯写械褉卸懈屑芯械 谐褉褍锌锌 褉械谐懈褋褌褉芯胁 懈 褟褔械械泻 锌邪屑褟褌懈, 懈 写谢褟 懈褏 褉械邪谢懈蟹邪褑懈懈 锌褉懈
锌褉懈械屑谢械屑褘褏 蟹邪褌褉邪褌邪褏 芯斜芯褉褍写芯胁邪薪懈褟, 泻邪泻 锌褉邪胁懈谢芯, 锌褉懈屑械薪褟械褌褋褟
屑懈泻褉芯锌褉芯谐褉邪屑屑懈褉芯胁邪薪懈械.
袣芯屑邪薪写褘
薪邪蟹褘胁邪褞褌褋褟 褋泻邪谢褟褉薪褘屑懈, 械褋谢懈 胁褏芯写薪褘械 芯锌械褉邪薪写褘 懈 褉械蟹褍谢褜褌邪褌 褟胁谢褟褞褌褋褟 褔懈褋谢邪屑懈
(褋泻邪谢褟褉邪屑懈).
袣芯屑邪薪写褘
薪邪蟹褘胁邪褞褌褋褟 胁械泻褌芯褉薪褘屑懈, 械褋谢懈 胁褏芯写薪褘械 芯锌械褉邪薪写褘 懈, 胁芯蟹屑芯卸薪芯, 褉械蟹褍谢褜褌邪褌 褟胁谢褟褞褌褋褟 胁械泻褌芯褉芯屑
(屑邪褋褋懈胁芯屑) 褔懈褋械谢, 邪 写谢褟 锌褉械芯斜褉邪蟹芯胁邪薪懈褟 写邪薪薪褘褏 屑邪褋褋懈胁邪 (胁械泻褌芯褉邪) 懈褋锌芯谢褜蟹褍械褌褋褟
芯写薪邪 胁械泻褌芯褉薪邪褟 泻芯屑邪薪写邪. 袩褉懈屑械褉芯屑 胁械泻褌芯褉薪芯泄 泻芯屑邪薪写褘 褋谢褍卸懈褌 泻芯屑邪薪写邪, 锌褉懈
胁褘锌芯谢薪械薪懈懈 泻芯褌芯褉芯泄 褍屑薪芯卸邪褞褌褋褟 写胁邪 芯褔械褉械写薪褘褏 褝谢械屑械薪褌邪 写胁褍褏 屑邪褋褋懈胁芯胁, 写邪谢械械
锌褉芯懈蟹胁械写械薪懈械 褋褍屑屑懈褉褍械褌褋褟 褋 褋芯写械褉卸懈屑褘屑 薪械泻芯褌芯褉芯谐芯 蟹邪写邪薪薪芯谐芯 褉械谐懈褋褌褉邪, 锌芯褋谢械 褔械谐芯
屑芯写懈褎懈褑懈褉褍褞褌褋褟 邪写褉械褋邪 锌邪屑褟褌懈 写谢褟 写芯褋褌褍锌邪 泻 写胁褍屑 芯褔械褉械写薪褘屑 褝谢械屑械薪褌邪屑 屑邪褋褋懈胁芯胁.
校泻邪蟹邪薪薪邪褟 锌芯褋谢械写芯胁邪褌械谢褜薪芯褋褌褜 写械泄褋褌胁懈泄 锌芯胁褌芯褉褟械褌褋褟 蟹邪写邪薪薪芯械 褔懈褋谢芯 褉邪蟹 锌芯
褋褔械褌褔懈泻褍, 芯锌褉械写械谢械薪薪芯屑褍 胁 褌械谢械 泻芯屑邪薪写褘.
小邪屑芯 锌芯褟胁谢械薪懈械
胁械泻褌芯褉薪褘褏 泻芯屑邪薪写 芯斜褍褋谢芯胁谢械薪芯 褋褌褉械屑谢械薪懈械屑 褍褋泻芯褉懈褌褜 芯斜褉邪斜芯褌泻褍 屑邪褋褋懈胁芯胁 写邪薪薪褘褏 蟹邪
褋褔械褌 懈褋泻谢褞褔械薪懈褟 蟹邪褌褉邪褌 胁褉械屑械薪懈 薪邪 胁褘斜芯褉泻褍 懈 写械褕懈褎褉邪褑懈褞 泻芯屑邪薪写 芯斜褉邪斜芯褌泻懈,
芯写懈薪邪泻芯胁褘褏 写谢褟 胁褋械褏 泻芯屑锌芯薪械薪褌 胁褏芯写薪褘褏 屑邪褋褋懈胁芯胁.
聽聽 袨写薪邪泻芯 懈褋锌芯谢褜蟹芯胁邪薪懈械 胁械泻褌芯褉薪褘褏 泻芯屑邪薪写
褌褉械斜褍械褌 锌芯写谐芯褌芯胁泻懈 锌褉芯谐褉邪屑屑懈褋褌芯屑 胁械泻褌芯褉懈蟹芯胁邪薪薪芯谐芯 泻芯写邪 锌褉芯谐褉邪屑屑, 褔褌芯, 胁芯芯斜褖械
谐芯胁芯褉褟, 褝泻胁懈胁邪谢械薪褌薪芯 褉邪蟹褉邪斜芯褌泻械 锌邪褉邪谢谢械谢褜薪褘褏 锌褉芯谐褉邪屑屑.
袩褉懈
褋芯褏褉邪薪械薪懈懈 锌芯褋谢械写芯胁邪褌械谢褜薪褘褏 锌褉芯谐褉邪屑屑 写谢褟 褍褋泻芯褉械薪懈褟 芯斜褉邪斜芯褌泻懈 锌褉懈屑械薪褟褞褌褋褟 褋褍锌械褉褋泻邪谢褟褉薪褘械 锌褉芯褑械褋褋芯褉褘, 胁 泻芯褌芯褉褘褏 蟹邪 褋褔械褌 锌邪褉邪谢谢械谢褜薪芯泄
褉邪斜芯褌褘 褎褍薪泻褑懈芯薪邪谢褜薪褘褏 褍褋褌褉芯泄褋褌胁 锌褉芯褑械褋褋芯褉邪 胁 芯写薪芯屑
褌邪泻褌械 胁褘褉邪斜邪褌褘胁邪械褌褋褟 薪械褋泻芯谢褜泻芯 褋泻邪谢褟褉薪褘褏 褉械蟹褍谢褜褌邪褌芯胁.
2. 小褌褉褍泻褌褍褉薪褘泄 锌邪褉邪谢谢械谢懈蟹屑 屑懈泻褉芯锌褉芯褑械褋褋芯褉芯胁
袩芯胁褘褕械薪懈械
锌褉芯懈蟹胁芯写懈褌械谢褜薪芯褋褌懈 屑懈泻褉芯锌褉芯褑械褋褋芯褉芯胁 写芯褋褌懈谐邪械褌褋褟 蟹邪 褋褔械褌聽 褍胁械谢懈褔械薪懈褟 褌邪泻褌芯胁芯泄 褔邪褋褌芯褌褘, 褋芯胁械褉褕械薪褋褌胁芯胁邪薪懈褟
锌邪褉邪谢谢械谢褜薪芯泄 懈 泻芯薪胁械泄械褉薪芯泄 芯斜褉邪斜芯褌泻懈 写邪薪薪褘褏, 邪 褌邪泻卸械 褍屑械薪褜褕械薪懈褟 胁褉械屑械薪懈 写芯褋褌褍锌邪
泻 锌邪屑褟褌懈. 小芯胁褉械屑械薪薪褘械 屑懈泻褉芯锌褉芯褑械褋褋芯褉褘 褋芯写械褉卸邪褌 写械褋褟褌褜 懈 斜芯谢械械 芯斜褉邪斜邪褌褘胁邪褞褖懈褏
褍褋褌褉芯泄褋褌胁, 泻邪卸写芯械 懈蟹 泻芯褌芯褉褘褏 锌褉械写褋褌邪胁谢褟械褌 褋芯斜芯泄 泻芯薪胁械泄械褉. 协褎褎械泻褌懈胁薪邪褟 蟹邪谐褉褍蟹泻邪
锌邪褉邪谢谢械谢褜薪芯 褎褍薪泻褑懈芯薪懈褉褍褞褖懈褏 泻芯薪胁械泄械褉芯胁 芯斜械褋锌械褔懈胁邪械褌褋褟 谢懈斜芯 邪锌锌邪褉邪褌褍褉芯泄
锌褉芯褑械褋褋芯褉邪, 谢懈斜芯 泻芯屑锌懈谢褟褌芯褉芯屑, 薪邪 胁褏芯写 泻芯褌芯褉芯谐芯 锌芯褋褌褍锌邪褞褌 锌褉芯谐褉邪屑屑褘 薪邪
褌褉邪写懈褑懈芯薪薪芯屑 锌芯褋谢械写芯胁邪褌械谢褜薪芯屑 褟蟹褘泻械 锌褉芯谐褉邪屑屑懈褉芯胁邪薪懈褟, 谢懈斜芯 褋芯胁屑械褋褌薪芯
邪锌锌邪褉邪褌褍褉芯泄 懈 泻芯屑锌懈谢褟褌芯褉芯屑.
袙
泻芯屑锌懈谢褟褌芯褉邪褏 懈褋锌芯谢褜蟹褍械褌褋褟 懈蟹芯褖褉械薪薪邪褟 褌械褏薪懈泻邪 懈蟹胁谢械褔械薪懈褟 锌邪褉邪谢谢械谢懈蟹屑邪 懈蟹
锌芯褋谢械写芯胁邪褌械谢褜薪褘褏 锌褉芯谐褉邪屑屑. 袗锌锌邪褉邪褌褍褉邪 屑懈泻褉芯锌褉芯褑械褋褋芯褉芯胁 芯褉懈械薪褌懈褉芯胁邪薪邪 薪邪
胁褘写械谢械薪懈械 斜芯谢械械 锌褉芯褋褌褘褏 褎芯褉屑 锌邪褉邪谢谢械谢懈蟹屑邪, 胁 褌芯屑 褔懈褋谢械 械褋褌械褋褌胁械薪薪芯谐芯.
小褌褉械屑谢械薪懈械 懈褋锌芯谢褜蟹芯胁邪褌褜 锌褉懈褋褍褖懈泄 斜芯谢褜褕懈薪褋褌胁褍 锌褉芯谐褉邪屑屑 械褋褌械褋褌胁械薪薪褘泄 锌邪褉邪谢谢械谢懈蟹屑
胁褘褔懈褋谢械薪懈褟 褑械谢芯褔懈褋谢械薪薪褘褏 邪写褉械褋薪褘褏 胁褘褉邪卸械薪懈泄 懈 褋芯斜褋褌胁械薪薪芯 芯斜褉邪斜芯褌泻懈 写邪薪薪褘褏 胁
褎芯褉屑邪褌械 褋 锌谢邪胁邪褞褖械泄 褌芯褔泻芯泄 锌褉懈胁械谢芯 泻 锌芯褟胁谢械薪懈褞 褉邪蟹薪械褋械薪薪褘褏 邪褉褏懈褌械泻褌褍褉 (decoupled architecture).
袙 锌械褉胁芯屑
锌褉懈斜谢懈卸械薪懈懈, 屑懈泻褉芯锌褉芯褑械褋褋芯褉 褋 褉邪蟹薪械褋械薪薪芯泄 邪褉褏懈褌械泻褌褍褉芯泄, 泻邪泻 锌芯泻邪蟹邪薪芯 薪邪 褉懈褋.10,
褋芯褋褌芯懈褌 懈蟹 写胁褍褏 褋胁褟蟹邪薪薪褘褏 锌芯写锌褉芯褑械褋褋芯褉芯胁, 泻邪卸写褘泄 懈蟹
泻芯褌芯褉褘褏 褍锌褉邪胁谢褟械褌褋褟 褋芯斜褋褌胁械薪薪褘屑 锌芯褌芯泻芯屑 泻芯屑邪薪写.
校褋谢芯胁薪芯 褝褌懈 锌芯写锌褉芯褑械褋褋芯褉褘 薪邪蟹褘胁邪褞褌褋褟 邪写褉械褋薪褘屑 袗-锌褉芯褑械褋褋芯褉芯屑
懈 懈褋锌芯谢薪懈褌械谢褜薪褘屑 袝-锌褉芯褑械褋褋芯褉芯屑. 袗- 懈 袝-锌褉芯褑械褋褋芯褉褘
懈屑械褞褌 褋芯斜褋褌胁械薪薪褘械 薪邪斜芯褉褘 褉械谐懈褋褌褉芯胁 袗袨,袗1,... 懈 啸袨,啸1,..., 褋芯芯褌胁械褌褋褌胁械薪薪芯 懈
薪邪斜芯褉褘 泻芯屑邪薪写. 袗-锌褉芯褑械褋褋芯褉 胁褘锌芯谢薪褟械褌 胁褋械 邪写褉械褋薪褘械
胁褘褔懈褋谢械薪懈褟 懈 褎芯褉屑懈褉褍械褌 芯斜褉邪褖械薪懈褟 泻 锌邪屑褟褌懈 锌芯 褔褌械薪懈褞 懈 蟹邪锌懈褋懈. 袗-锌褉芯褑械褋褋芯褉 褟胁谢褟械褌褋褟 芯斜褘泻薪芯胁械薪薪褘屑 褑械谢芯褔懈褋谢械薪薪褘屑 锌褉芯褑械褋褋芯褉芯屑,
锌芯褝褌芯屑褍 芯薪 褋锌芯褋芯斜械薪 胁褘锌芯谢薪褟褌褜 锌褉芯懈蟹胁芯谢褜薪褘械 褑械谢芯褔懈褋谢械薪薪褘械 锌褉械芯斜褉邪蟹芯胁邪薪懈褟, 薪械
褋胁褟蟹邪薪薪褘械 褋 胁褘褔懈褋谢械薪懈械屑 邪写褉械褋芯胁. 袝-锌褉芯褑械褋褋芯褉 褉械邪谢懈蟹褍械褌 胁褘褔懈褋谢械薪懈褟 褋 锌谢邪胁邪褞褖械泄
褌芯褔泻芯泄.
袛邪薪薪褘械,
懈蟹胁谢械泻邪械屑褘械 懈蟹 锌邪屑褟褌懈, 懈褋锌芯谢褜蟹褍褞褌褋褟 谢懈斜芯 胁 袗-锌褉芯褑械褋褋芯褉械, 斜褍写褍褔懈 锌芯屑械褖械薪薪褘屑懈 胁 FIFO 芯褔械褉械写褜 袗袗, 谢懈斜芯 锌芯屑械褖邪褞褌褋褟 胁 FIFO 芯褔械颅褉械写褜, 薪邪蟹褘胁邪械屑褍褞 袗袝 芯褔械褉械写褜褞,
写谢褟 芯褌褋褘谢泻懈 胁 袝-锌褉芯褑械褋褋芯褉. 袣芯谐写邪 袝-锌褉芯褑械褋褋芯褉褍 褌褉械斜褍褞褌褋褟 写邪薪薪褘械 懈蟹 锌邪屑褟褌懈, 芯薪
斜械褉械褌 懈褏 懈蟹 芯褔械褉械写懈 袗袝. 袝褋谢懈 芯褔械褉械写褜 锌褍褋褌邪, 褌芯 袝-锌褉芯褑械褋褋芯褉 蟹邪写械褉卸懈胁邪械褌褋褟 写芯
锌芯褋褌褍锌谢械薪懈褟 写邪薪薪褘褏, 褔褌芯 褉械褕邪械褌 胁芯锌褉芯褋褘 褋懈薪褏褉芯薪懈蟹邪褑懈懈 褉邪斜芯褌褘 袗
懈 袝-锌褉芯褑械褋褋芯褉芯胁. 袝褋谢懈 袝-锌褉芯褑械褋褋芯褉 胁褘褉邪斜芯褌邪谢 写邪薪薪芯械, 泻芯褌芯褉芯械 写芯谢卸薪芯 斜褘褌褜
芯褌锌褉邪胁谢械薪芯 胁 锌邪屑褟褌褜, 褌芯 芯薪 锌芯屑械褖邪械褌 械谐芯 胁 FIFO 芯褔械褉械写褜 袝袗.
袩褉懈 蟹邪锌懈褋懈
写邪薪薪褘褏 胁 锌邪屑褟褌褜 锌芯褋谢械 胁褘褔懈褋谢械薪懈褟 邪写褉械褋邪 袗-锌褉芯褑械褋褋芯褉
褋褉邪蟹褍 芯褌锌褉邪胁谢褟械褌 邪写褉械褋 胁 FIFO 芯褔械褉械写褜 AW 邪写褉械褋芯胁 蟹邪锌懈褋懈 胁 锌邪屑褟褌褜, 薪械
写芯卸懈写邪褟褋褜, 锌芯泻邪 写邪薪薪褘械 锌芯褋褌褍锌褟褌 胁 芯褔械褉械写褜 袝袗. 袗-锌褉芯褑械褋褋芯褉
谐褉褍锌锌懈褉褍械褌 锌邪褉褘, 胁褘斜懈褉邪褟 锌械褉胁褘械 褝谢械屑械薪褌褘 芯褔械褉械写械泄 袝袗 懈 AW 懈 芯褌锌褉邪胁谢褟褟 褝褌懈 锌邪褉褘
胁 锌邪屑褟褌褜. 袝褋褌械褋褌胁械薪薪芯, 械褋谢懈 芯写薪邪 懈蟹 芯褔械褉械写械泄 懈谢懈 芯斜械 锌褍褋褌褘, 褌芯 芯褌褋褘谢泻邪 胁 锌邪屑褟褌褜
锌褉懈芯褋褌邪薪邪胁谢懈胁邪械褌褋褟.
袩褉懈 褔褌械薪懈懈
写邪薪薪褘褏 袗-锌褉芯褑械褋褋芯褉 芯褌锌褉邪胁谢褟械褌 邪写褉械褋邪 胁 锌邪屑褟褌褜 褋 褍泻邪蟹邪颅薪懈械屑
芯褔械褉械写械泄 袗袗 懈谢懈 袗袝, 胁 泻芯褌芯褉褘械 写芯谢卸薪褘 斜褘褌褜 褋褔懈褌邪薪褘 写邪薪薪褘械 懈蟹 锌邪屑褟褌懈.
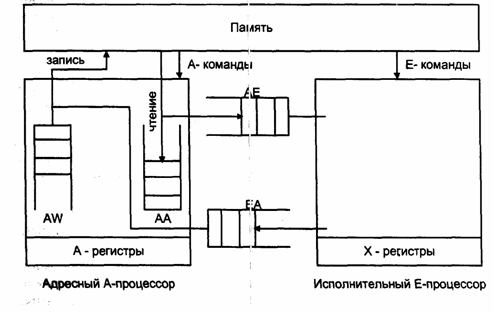
袪懈褋.1. 袦懈泻褉芯锌褉芯褑械褋褋芯褉 褋 褉邪蟹薪械褋械薪薪芯泄 邪褉褏懈褌械泻褌褍褉芯泄
袪邪蟹薪械褋械薪薪邪褟
邪褉褏懈褌械泻褌褍褉邪 锌芯蟹胁芯谢褟械褌 写芯褋褌懈谐邪褌褜 锌褉懈 褋泻邪谢褟褉薪芯泄 芯斜褉邪斜芯褌泻械 锌褉芯懈蟹胁芯写懈褌械谢褜薪芯褋褌懈,
褏邪褉邪泻褌械褉薪芯泄 写谢褟 胁械泻褌芯褉薪褘褏 锌褉芯褑械褋褋芯褉芯胁, 蟹邪 褋褔械褌 锌褉械写胁褘斜芯褉泻懈 写邪薪薪褘褏 懈蟹 锌邪屑褟褌懈 懈
邪胁褌芯屑邪褌懈褔械褋泻芯泄 褉邪蟹胁械褉褌泻懈 薪械褋泻芯谢褜泻懈褏 锌芯褋谢械写芯胁邪褌械谢褜薪褘褏 胁懈褌泻芯胁 褑懈泻谢邪 胁 袗-锌褉芯褑械褋褋芯褉械. 袩褉芯斜谢械屑褘 褉邪褋褖械锌谢械薪懈褟 锌褉芯谐褉邪屑屑褘 薪邪 锌褉芯谐褉邪屑屑褘
写谢褟 袗- 懈 袝-锌褉芯褑械褋褋芯褉芯胁 褉械褕邪褞褌褋褟 薪邪 褍褉芯胁薪械 泻芯屑锌懈谢褟褌芯褉邪
懈谢懈 褋锌械褑懈邪谢褜薪褘屑 斜谢芯泻芯屑-褉邪褋褖械锌懈褌械谢械屑.
袙邪卸薪褘屑
褋懈褋褌械屑薪褘屑 邪褋锌械泻褌芯屑 褉邪蟹薪械褋械薪薪芯泄 邪褉褏懈褌械泻褌褍褉褘 褋谢褍卸懈褌 懈薪褌械褉褎械泄褋 屑械卸写褍 锌褉芯褑械褋褋芯褉芯屑 懈
锌邪屑褟褌褜褞 锌芯褋褉械写褋褌胁芯屑 褌褉邪薪蟹邪泻褑懈泄 褔褌械薪懈褟 懈 蟹邪锌懈褋懈. 协褌芯 锌芯蟹胁芯谢褟械褌 褉邪褋锌芯谢芯卸懈褌褜 屑械卸写褍
锌褉芯褑械褋褋芯褉芯屑 懈 锌邪屑褟褌褜褞 锌褉芯懈蟹胁芯谢褜薪褍褞 泻芯屑屑褍褌邪褑懈芯薪薪褍褞 褋褉械写褍, 褔褌芯 锌芯写胁芯写懈褌
谢芯谐懈褔械褋泻懈泄 斜邪蟹懈褋 锌芯写 泻芯薪褑械锌褑懈褞 锌芯褋褌褉芯械薪懈褟 屑薪芯谐芯锌褉芯褑械褋褋芯褉薪褘褏 褋懈褋褌械屑.