Исполнение процессорами инструкций x86 и x64 (Лекция)
ПЛАН ЛЕКЦИИ
– Кэш инструкций
– Предсказание переходов
– Исполнение инструкций
– Внеочередное исполнение
операций, функциональные устройства
Кэш инструкций
Во всех современных микроархитектурах, за исключением
процессора P-4, кэш инструкций
(I-кэш) организован классическим образом.
Кэш 1-го уровня (L1-кэш) имеет размер 32 Кбайт и состоит из блоков по
64 байта, организованных в виде 64 наборов по 8 блоков. Для поиска требуемого
элемента данных в кэше используется комбинированный
алгоритм, сочетающий прямую адресацию по нескольким разрядам адреса с
ассоциативным поиском. Младшие 6 разрядов адреса b5-0 указывают положение байта
в 64-байтовом блоке и для поиска блока не используются. Следующие 6 разрядов адреса
b11-6 указывают номер набора, а нахождение требуемого блока в наборе
осуществляется сравнением самых старших разрядов адреса (ключа) с
соответствующими разрядами адреса, хранящимися для каждого блока в наборе
(тэгами). Таким образом, элемент данных по какому-либо адресу может
располагаться в рассматриваемом кэше в одном из 8
блоков конкретного набора.
Если нужный блок данных не найден в L1-кэше, он ищется в кэше второго уровня (L2-кэше), и далее, если не найден и
там, в оперативной памяти. Затем этот блок записывается в L1-кэш. Если все
блоки в наборе уже заняты, то один из блоков удаляется (вытесняется). Как
правило, для вытеснения используется алгоритм LRU (Least
Recently Used — «наименее
используемый в последнее время»).
Описанная организация кэша называется
«наборно-ассоциативной» (set-associative). Число
блоков в наборе (в данном случае 8) называется уровнем ассоциативности кэша. Оно определяет, сколько блоков данных, отстоящих друг
от друга на расстоянии с определённой кратностью (в данном случае –
кратном 4 Кбайт), может одновременно находиться в кэше.
Данное ограничение называют проблемой алиасинга. Чем
выше уровень ассоциативности, тем меньше вероятность, что различные блоки
данных столкнутся с алиасингом. Например, у L1-кэшей
процессора K8 уровень ассоциативности равен 2 при размере 64 Кбайт, а I-кэш
процессора PPC970 имеет уровень ассоциативности, равный 1 при том же размере 64
Кбайт (такая организация называется прямым отображением), и состоит из блоков
по 128 байт.
Обычно поиск в кэшах осуществляется по
физическому адресу элемента данных. Однако преобразование
адреса из программного (логического) в физический требует определённого времени
– для этого используется вспомогательная структура, похожая на небольшой кэш и
называемая буфером преобразования адреса
(TLB, Translation Lookaside
Buffer). Поэтому для адресации набора L1-кэша,
чтобы ускорить поиск, используют необходимые разряды программного адреса. В тех
случаях, когда эти разряды адресуют не больше одной страницы памяти (размер
которой, как правило, равен 4 Кбайт), они совпадают с соответствующими
разрядами физического адреса. Например, в процессорах P-M и P8 для этого
используются разряды b11-6, и данное условие соблюдается. Арифметически это
условие можно выразить так: частное от деления размера кэша
на уровень ассоциативности не должно превышать размера страницы. Легко видеть,
что в процессорах K8 и PPC970 данное условие не соблюдается (64K/2=32K,
64K/1=64K).
В I-кэше процессора K8, помимо байтов
инструкций, хранятся также так называемые биты предекодирования
— по 3 разряда на байт. Их назначение будет описано в разделе про
декодирование.
Инструкции считываются из I-кэша порциями
(выровненными блоками), с опережающей предвыборкой, чтобы обеспечить
бесперебойную работу декодера инструкций и ускорить предсказание переходов.
Размер такого блока в процессорах P-III и K8 равен 16 байтам.
Предсказание переходов
Механизм предсказания переходов
выполняет две основные функции – предсказание программного адреса инструкции,
на которую производится переход (для всех инструкций перехода), и предсказание
направления ветвления (для инструкций условного перехода). Оба предсказания
должны быть выполнены заблаговременно – раньше, чем начнётся декодирование и
обработка инструкции перехода – для того, чтобы выборка нового блока инструкций
была произведена без потерь лишних тактов либо с минимальными потерями.
Необходимость предсказания адреса «целевой» инструкции вызвана тем, что
этот адрес может быть извлечён из x86-инструкции перехода и вычислен только на
финальной стадии декодирования, с большой задержкой. Более того, даже простое
выделение инструкций переменной длины из считанного блока и поиск среди них
инструкций перехода займёт какое-то время. Поэтому в процессорах архитектуры
x86 предсказание производят по целому блоку, без разбиения его на составляющие
инструкции.
В современных процессорах для предсказания адреса перехода обычно
используют специальную таблицу адресов
переходов BTB (Branch Target
Buffer). Эта таблица устроена подобно кэшу и содержит адреса инструкций, на которые ранее
производились переходы. Например, в процессоре P-III таблица BTB имеет размер
512 элементов и организована в виде 128 наборов с ассоциативностью 4. Для
адресации набора используются младшие разряды адреса 16-байтового блока инструкций
(b10-4). Если в этом блоке есть инструкции перехода, и если эти инструкции
отрабатывали ранее, то алгоритм предсказания может очень быстро найти адрес
целевой инструкции в таблице BTB и начать считывание блока, содержащего эту
инструкцию. Адреса целевых инструкций помещаются в BTB в момент отставки
соответствующих инструкций перехода.
В более новых процессорах размер таблицы BTB достигает 2048 элементов
(K8) и 4096 элементов (P-4). Организация данной подсистемы в процессоре K8
несколько отличается от классической
и основывается на предварительной разметке блоков инструкций в так называемых
массивах селекторов перед помещением их в I-кэш. Эти селекторы привязаны к
положению инструкций в I-кэше и при их вытеснении
оттуда сохраняются в L2-кэше (в так называемых
ECC-битах, предназначающихся для коррекции ошибок). Элементы таблицы BTB также
привязаны к положению инструкций в I-кэше и теряются
при их вытеснении. Это несколько снижает эффективность предсказания адресов
переходов в процессоре K8.
Для предсказания направления условного перехода используется другой
механизм, основанный на изучении поведения переходов в программе в процессе её
выполнения (своего рода «сбор статистики»). Этот механизм учитывает как
локальное поведение конкретной инструкции перехода (например, «как правило,
переходит», «как правило, не переходит»), так и глобальные закономерности
(«чередуется по определённому закону» и т.п.). История поведения инструкций
условного перехода записывается в специальных структурах, обычно называемых «таблицами
истории переходов» (Branch History
Table, BHT). Современные механизмы предсказания
переходов обеспечивают правильное предсказание более чем в 90 процентах
случаев.
Механизм предсказания переходов работает одновременно с декодером
инструкций и независимо от него. Благодаря эффективной реализации предсказания
адреса перехода в процессорах P-III, P-M, P-M2, P8 и K8 при правильном
предсказании теряется всего 1 такт. Это означает, что минимальное время,
затрачиваемое на итерацию цикла (либо на один переход в цепочке переходов),
составляет 2 такта. По существу, предсказатель переходов в таком цикле (или
цепочке) работает в своём независимом цикле, состоящем из двух стадий –
предсказания и считывания нового блока кэша – а
декодер и прочие подсистемы процессора обрабатывают инструкции из вновь
считываемых блоков. Поскольку предсказатель переходов «просматривает» целый
блок, который может содержать большое число инструкций, то он может «опережать»
декодер в своём просмотре. Благодаря этому переход может быть совершён раньше,
чем исчерпаются инструкции в текущем блоке, и указанной потери такта не
произойдёт – этот такт будет скрыт на фоне бесперебойной работы декодера.
Когда инструкция перехода попадёт в функциональное устройство для
исполнения, будет выяснено, правильно предсказан этот переход или нет. В момент
её отставки при неправильном предсказании перехода все последующие инструкции
будут отменены, и начнётся считывание инструкций из I-кэша
по правильному адресу. Такую процедуру называют сбросом конвейера, а время (в
тактах), которое было потрачено на выполнение инструкции перехода с момента её
считывания из кэша, называют длиной конвейера непредсказанного перехода. Это время характеризует чистую
потерю в идеальных условиях, когда инструкция проходила через все этапы
«гладко» и нигде не задерживалась по внешним причинам. В реальных условиях
потеря на неправильно предсказанный переход может оказаться выше.
Длина конвейера непредсказанного перехода не
всегда указывается в документации и известна весьма приблизительно.
Её довольно трудно замерить, так как современные предсказатели переходов
работают достаточно эффективно и не позволяют добиться гарантированной доли
неправильных предсказаний в тестах. Можно дать следующие примерные оценки длины
конвейера: P-III – 11, P-M – 12, P-4 – 20, P-4E – 30, P8 – 14, K8 – 11, PPC970
– 13.
Кэш инструкций в процессоре P-4 очень сильно отличается от I-кэша в процессоре классической архитектуры. В нём
преобразование исходных x86-инструкций в МОПы
производится перед кэшем, а в кэш помещаются целые
трассы, составленные из этих МОПов. Поэтому такой кэш
в процессоре P-4 называется «кэш трасс» (Trace-cache,
Т-кэш). Об устройстве T-кэша можно
прочитать в статье, адрес которой в Интернете приведён в конце данной лекции.
Исполнение инструкций
Большинство процессоров обрабатывают и исполняют инструкции архитектуры
x86 (называемой также IA-32) и расширенной архитектуры x86-64 (называемой также
AMD64 либо EM64T). Принципиальных различий по структуре машинной инструкции
между архитектурами x86 и x86-64 нет, поэтому по тексту будем везде
использовать общее наименование «x86-инструкции». Эти инструкции имеют очень
сложный и нерегулярный формат и могут состоять из нескольких составных частей:
одного или нескольких однобайтных префиксов, кода операции длиной от 1 до 3
байтов, описателя типа адресации операндов (ModR/M),
указателя регистров базы, индекса и масштаба индексирования (SIB), поля
смещения адреса и непосредственного операнда. Длина x86-инструкции может
варьироваться от 1 до 15 байтов.
Для суперскалярной обработки необходимо в
каждом такте извлекать из входного потока несколько инструкций переменной длины
и отправлять каждую из них в отдельный блок декодирования для преобразования в
микрооперации (МОПы). Эта задача представляется очень
трудоёмкой, поэтому необходимо применение специальных средств, которые
позволили бы её облегчить. В разных процессорах x86 используются различные
приёмы и механизмы, обеспечивающие бесперебойную обработку инструкций. Лишь для
процессора PPC970 не требуется никаких ухищрений, так как в RISC-архитектуре
IBM Power машинные инструкции имеют фиксированную
длину (4 байта) и регулярный формат. По типу используемых механизмов
рассматриваемые процессоры можно разбить на четыре класса:
PPC970: Не используется никакой механизм, так как инструкции имеют
фиксированную длину и формат.
P-III, P8: После выборки из I-кэша
производится разметка инструкций (определение их границ и положения кода
операции) в устройстве, называемом определителем длины инструкций (Instruction Length Decoder, ILD).
K8: Перед помещением блоков инструкций в I-кэш производится
предварительное декодирование (предекодирование) с
аналогичной разметкой, информация о разметке записывается в дополнительные биты
при каждом байте в I-кэше.
P-4: Перед помещением в кэш производится полное декодирование
инструкций, сформированные МОПы записываются в этот
кэш (Т-кэш) в виде трасс.
Ниже будет для примера рассмотрен процесс исполнения инструкций только
для архитектуры P-III и P-8.
Более подробно об исполнении инструкций процессорами
другой архитектуры можно узнать из статьи, ссылка на которую сделана в конце
лекции.
Процессоры Intel Pentium III, Pentium M и Core Duo
В процессорах семейства P6 инструкции считываются из I-кэша выровненными блоками по 16 байтов за такт. Выборка
производится с опережением – у процессора есть два буфера, в которые помещаются
два последних считанных блока. На вход подсистемы декодирования в каждом такте
передаётся порция байтов, начинающаяся с того места, где была прекращена
обработка в предыдущем такте. Длина этой порции ограничена также 16 байтами.
Порция байтов поступает на вход определителя
длины инструкций (ILD), который производит её разметку – нахождение
границ и положения кода операции в каждой x86-инструкции.
Определитель длины инструкций должен быть обязательно реализован неконвейерным образом, с временем
работы 1 такт – так как в следующем такте надо будет размечать новую порцию,
начинающуюся после последней инструкции, размеченной в данном такте.
Определитель содержит 16 одинаковых устройств, построенных на основе программируемых логических матриц
(PLA). На вход каждого такого устройства подаётся фрагмент кода длиной 4 байта,
начинающийся с одного из 16 байтов в обрабатываемой порции. Устройство (PLA)
представляет собой примитивный декодер, который предполагает, что данный
фрагмент является началом x86-инструкции (без префиксов), и пытается определить
её длину. Кроме того, это устройство анализирует первый байт в
фрагменте и определяет, не может ли он являться префиксом.
Результаты работы всех таких устройств собираются воедино с помощью
цепочки схем быстрого переноса. По
существу, эти схемы последовательно выстраивают список инструкций на основе
данных о длинах и признаках наличия префиксов, начиная с первой инструкции в
обрабатываемой порции байтов. По результатам этого выстраивания в специальных
массивах делаются пометки о позициях кода операции и последнего байта в каждой
инструкции. Эта информация используется в последующем такте для извлечения
инструкций из буфера и передачи их на вход трёх каналов декодера.
В некоторых случаях определитель длины инструкций не может произвести
разметку за один такт. Например, если встречается префикс,
меняющий длину непосредственного операнда или смещения адреса в инструкции с 16
бит на 32 бита, либо наоборот, определитель переходит в «медленный»
режим, размечая по 4 байта за такт. Однако такие случаи не часты и по существу
представляют собой нарушение правил программирования. Кроме того, разметка
замедляется, если в какой-то инструкции встречается два или более префиксов – в
этом случае обработка каждого дополнительного префикса занимает один такт. На
практике эта ситуация также очень редка.
После разметки три выделенные x86-инструкции передаются в основной
декодер – точнее, в три параллельно работающих канала декодирования. Эти три
канала не являются полностью симметричными – только первый из них может
обработать любую инструкцию, а оставшиеся два имеют ограничения: инструкция
должна иметь длину до 8 байтов и порождать только один МОП. У первого канала
декодирования таких ограничений нет – он может породить до 4 МОПов в одном такте, параллельно с работой двух других
каналов. Для обработки самых сложных инструкций (более 4 МОПов)
требуются дополнительные такты, и в этом случае обработка ведётся
последовательно.
Таким образом, схему работы декодера в процессоре P-III можно
обозначить как «4-1-1 / >4»: он может обрабатывать в одном такте, либо три
инструкции, порождающие до 6 МОПов (4+1+1), либо
одну, порождающую более 4 МОПов. Порождаемые МОПы накапливаются в небольшой очереди перед отправкой
(группами по три) в последующие тракты процессора. Схема «4-1-1» накладывает
определённые ограничения на оптимальное размещение x86-инструкций в коде:
сложные инструкции (в частности, инструкции типа Load-Op)
должны чередоваться с простыми, а не следовать подряд
друг за другом. Впрочем, даже при плотном размещении нескольких сложных
инструкций всё равно в каждом такте будет порождаться как минимум 2 МОПа, а очередь МОПов после
декодера позволит сглаживать возникающие неравномерности.
В процессоре P-III при декодировании инструкций загрузки из памяти с
последующим исполнением (Load-Op) порождаются
отдельные МОПы для загрузки и для выполнения.
Аналогично, для инструкций выгрузки в память также порождаются два отдельных МОПа: для вычисления адреса, и для осуществления записи. В
обоих случаях два МОПа обслуживаются в последующих
трактах процессора по отдельности и занимают его ресурсы. Из-за частой
встречаемости инструкций, содержащих загрузку из памяти и выгрузку в память,
среднее число МОПов на одну x86-инструкцию может
находиться в диапазоне от 1.3 до 1.5.
Начиная с процессора P-M, в декодере реализован механизм «слияния
микроопераций» (micro-ops fusion),
когда порождается единый МОП, содержащий два элементарных действия. Разделение
на эти элементарные действия происходит при запуске МОПа
на исполнение. Механизм слияния микроопераций похож на аналогичный механизм в
процессорах AMD K7/K8. Этот механизм экономит ресурсы буферов и увеличивает
эффективную пропускную способность трактов процессора. Благодаря такому
механизму среднее число МОПов на одну x86-инструкцию
значительно снижается и становится близким к единице. Кроме того, инструкции Load-Op могут теперь обрабатываться во всех трёх каналах
декодера, что, практически, сводит на нет недостатки
несимметричной схемы «4-1-1».
Правда, в декодере процессоров P-III и P-M имеется ещё одно
ограничение, касающееся инструкций SSE. Эти инструкции могут обрабатываться
только в первом канале декодера — причём данное ограничение относится не только
к упакованным инструкциям SSE, расщепляемым на два МОПа,
но и к скалярным инструкциям тоже. Кроме того, на инструкции SSE с загрузкой из
памяти (Load-Op) не распространяется механизм слияния
микроопераций. Таким образом, скалярная инструкция SSE типа Load-Op
в процессоре P-M преобразуется в два МОПа, а
упакованная – в четыре. Данные ограничения связаны, скорее всего, со сложностью
реорганизации декодера для поддержки операций SSE.
В процессоре P-M2 (Core Duo)
декодер x86-инструкций был радикально переделан. Теперь он поддерживает слияние
микроопераций для инструкций Load-Op всех типов
(включая различные SSE, за исключением инструкций упаковки/распаковки), а также
обработку инструкций SSE (как скалярных, так и упакованных) во всех трёх
каналах декодера. В результате число МОПов,
порождаемых для скалярных инструкций SSE типа Load-Op,
снизилось с двух до одного, а для упакованных – с четырёх до двух. Предельная
пропускная способность декодера выросла в три раза – с одной инструкции SSE за
такт до трёх.
Схему декодера процессора P-M2 можно обозначить как «4-2-2 / >2». По
своей гибкости эта схема превосходит схему декодера процессора AMD K8 «2-2-2 /
>2» благодаря обработке сложных инструкций в первом канале декодера одновременно
с работой двух других каналов. Правда, декодер процессора K8 может порождать
два МОПа также для некоторых других типов инструкций
(не только SSE), но большинство таких инструкций в процессоре P-M2 являются
простыми, с преобразованием в один МОП.
Таким образом, последний представитель семейства P6/P6+ – процессор
P-M2 (Core Duo) – имеет
гибкий трёхканальный декодер, эффективно работающий с подавляющим большинством
x86-инструкций. Он в целом не уступает декодерам, реализованным с применением предекодирования перед помещением инструкций в I-кэш, и
лишён некоторых их недостатков. Применённая в декодере схема потребовала
введения сложного определителя длины инструкций и удлинения конвейера на один
такт.
Несмотря на то, что МОПы выходят из декодера
группами по три, в последующих трактах они обрабатываются и отслеживаются по
отдельности. В частности, в буфере переупорядочения они размещаются плотно, без
потери на фрагментацию, как это свойственно микроархитектурам,
в которых МОПы собираются в фиксированные группы с
привязкой позиции в группе к конкретным очередям и устройствам.
Одновременно с помещением новой группы МОПов
в буфер переупорядочения и в очередь планировщика производится переименование
(переназначение) регистров результатов для этих МОПов.
Каждой позиции буфера переупорядочения приписан один внутренний (физический)
регистр длиной 80 разрядов, который ставится в
соответствие исходному (архитектурному) регистру. Обратное копирование
содержимого физического регистра в соответствующий
архитектурный будет произведено в момент отставки операции. Для хранения одного
128-битного регистра XMM используются два внутренних регистра.
Внеочередное исполнение операций,
функциональные устройства
Подсистему внеочередного исполнения операций вместе с функциональными
устройствами объединяют под названием «Back End», чтобы подчеркнуть её обособленность и
самостоятельность. Внутри этой подсистемы обработка операций ведётся
асинхронно, с учётом зависимостей между ними, готовности операндов и наличия
требуемых ресурсов (устройств и очередей). При внеочередной обработке операций
в этой подсистеме гарантируется, что результаты такого выполнения программы
совпадут с результатами «правильного» последовательного выполнения.
Отставка выполненных машинных инструкций после их выхода из подсистемы
внеочередного исполнения производится строго последовательно. Таким образом,
восстанавливается натуральный порядок следования операций. Говорить о внешнем
или архитектурном состоянии программы можно только с позиции последней машинной
инструкции, покинувшей блок отставки. При возникновении какого-либо прерывания
все последующие инструкции будут считаться невыполненными вне зависимости от
действительного состояния их выполнения. При выходе из прерывания все эти
инструкции будут повторно исполнены с самого начала.
Ниже описана организация подсистемы внеочередного исполнения операций и
характеристики функциональных устройств, в которых эти операции выполняются.
Структура этой подсистемы связана с устройством подсистемы декодирования
инструкций, поэтому характеристики этих двух подсистем тесно переплетаются.
Здесь рассмотрена организация данной подсистемы только для архитектуры
процессоров P-III, P-M, а также Core Duo. Более
подробно об организация
подсистемы внеочередного исполнения операций другой архитектуры можно узнать из
статьи, ссылка на которую сделана в конце лекции.
После выхода из декодера сформированные группы по три МОПа помещаются в буфер переупорядочения ROB, длина
которого составляет 40 элементов (начиная с процессора P-M размер буфера ROB,
по некоторым данным, увеличен до 60-80 элементов). Новая группа МОПов также копируется в очередь планировщика RS, из
которой операции будут запускаться на исполнение. В процессоре P-III
используется единая очередь планировщика размером в 20 элементов (начиная с
процессоры P-M – 24 элемента), общая для всех типов операций. МОПы выбираются на исполнение из этой очереди во
внеочередном порядке, по мере готовности аргументов операций (рис. 4).
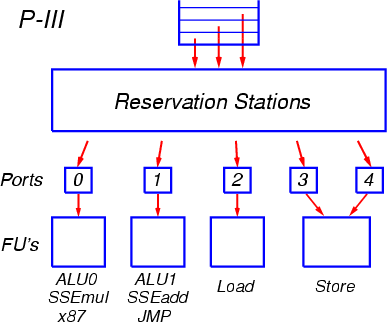
Рис. 4. Организация внеочередного
исполнения операций в процессорах архитектуры P-III,
P-M, Core Duo
МОПы отправляются на исполнение через так называемые порты запуска. Всего
таких портов пять: два для арифметико-логических операций (ALU), и три – для операций вычисления адресов и
для загрузки/выгрузки. К каждому из портов подсоединены соответствующие
функциональные устройства.
Порт 0 обслуживает устройства целочисленной арифметики и логики,
включая блоки для выполнения умножения и деления, а также устройства арифметики
с плавающей точкой x87 и устройство умножения SSE. К порту 1 подсоединено
другое устройство целочисленной арифметики и логики, частично дублирующее
аналогичное на порту 0, устройство для выполнения переходов, а также устройства
сложения и некоторых дополнительных операций SSE.
Начиная с процессора P-M, операции умножения и сложения с плавающей
точкой x87 разнесены по разным портам (по аналогии с операциями SSE): умножение
осталось на порту 0, а сложение переведено на порт 1. Также добавлены операции
SSE2 с аналогичным распределением между портами.
К портам 2 и 3 подсоединены устройства вычисления адресов для операций
загрузки из памяти и выгрузки в память, а к порту 4 – собственно устройство
выгрузки, готовящее данные для отсылки в память.
В процессоре P-III при декодировании инструкций загрузки из памяти с
последующим исполнением (Load-Op) порождаются
отдельные МОПы для загрузки и для выполнения. Оба
этих МОПа помещаются в буфер переупорядочения ROB и в
очередь планировщика RS и обслуживаются по отдельности. Начиная с процессора
P-M, в декодере реализован механизм «слияния микроопераций» (micro-ops fusion), когда
порождается единый МОП, содержащий два элементарных действия. Разделение на эти
элементарные действия, или микрооперации, происходит при их запуске на
исполнение (диспетчеризации) из очереди планировщика. Сначала запускается
микрооперация загрузки (через порт 2), а затем, в преддверии готовности
операнда – функциональная микрооперация (через порт 0 или 1).
Аналогично операциям загрузки для инструкций выгрузки в память в
процессоре P-III также порождаются два отдельных МОПа:
для вычисления адреса и для осуществления записи. Эти МОПы
запускаются (диспетчеризуются) по отдельности,
соответственно через порты 3 и 4. Начиная с процессора P-M, для инструкций
выгрузки порождается единый МОП, который разделяется на микрооперации при
запуске на исполнение.
Механизм слияния микроопераций позволяет экономить ресурсы буферов
внеочередного исполнения (ROB и RS), имеющих ограниченный размер, и увеличить
эффективную пропускную способность трактов процессора.
Через каждый из пяти портов может отсылаться на исполнение по одной
операции за такт. Таким образом, очередь планировщика представляет собой
полностью ассоциативный буфер с довольно сложной организацией. В каждом такте
может производиться поиск и извлечение до пяти элементов (МОПов)
из этого буфера, и одновременно в него может быть помещено три новых МОПа. Для отправки на исполнение в буфере ищутся операции,
аргументы которых уже вычислены либо вычисляются и будут готовы к моменту
попадания в функциональное устройство. Если для какого-то порта найдено
несколько таких готовых операций, среди них выбирается одна по алгоритму «псевдо-FIFO» (First
In, First Out). Этот алгоритм отдаёт предпочтение самым старым
операциям, однако выполняет поиск не совсем строго и точно, что связано со
сложностью реализации алгоритма с точным соблюдением старшинства. В результате
может оказаться, что 100-процентная скорость выполнения потока инструкций не
достигается даже при оптимальном потактовом планировании машинных инструкций
программистом или транслятором из-за того, что не в каждом такте через порты 0
и 1 запускаются две операции.
Латентность большинства операций целочисленной арифметики составляет 1
такт, а их суммарный темп исполнения – 2 операции за такт, по одной в устройствах,
подсоединённых к портам 0 и 1. Некоторые операции (сложения/вычитания и
копирования, а также логические) могут выполняться в устройствах на обоих
портах. Также в каждом такте может быть произведено одно считывание из L1-кэша
и одна запись в L1-кэш (64-разрядные).
Операции арифметики с плавающей точкой x87 выполняются в
соответствующем устройстве на порту 0 (начиная с процессора P-M – в раздельных
устройствах на портах 0 и 1). Операции сложения FADD могут стартовать в каждом
такте, а операции умножения FMUL – с интервалом в 2 такта. Чередуя сложение и
умножение, можно получить суммарный темп выполнения, равный одной операции за
такт. Латентность операции сложения составляет 3 такта, умножения – 5 тактов.
Операции перестановки регистров x87 в стеке (FXCH) отрабатывают на
стадии переименования регистров и поэтому не попадают в очереди планировщика и
в функциональные устройства. Темп обработки таких операций равен трём за такт.
Скалярные операции SSE исполняются в полном
темпе, упакованные операции – в половинном. Это связано с тем, что каждая упакованная
инструкция SSE преобразуется в два МОПа. С учётом
чередования сложения и умножения, суммарный темп выполнения составляет два МОПа за такт, что соответствует четырём 32-битным
арифметическим операциям для упакованного режима. Латентность операций сложения
и умножения SSE составляют соответственно 3 и 4 такта.
Операции сложения в 64-битном режиме SSE2 (начиная с процессора P-M)
также выполняются в полном темпе с латентностью 3 такта, а операции умножения —
в половинном темпе с латентностью 5 тактов. Таким образом, суммарный темп
выполнения таких операций при чередовании сложения и умножения составляет один
МОП за такт. На практике на процессоре P-III удаётся добиться уровня в 0.9-0.95
арифметической операции SSE2 за такт.
Таким образом, в процессоре P-III имеется ряд недостатков, ограничивающих его производительность. Главным из них является слабость блока плавающей арифметики при работе в 64-битном и 80-битном режимах (SSE2 и x87). Другим недостатком являются ограничения в планировщике, которые не позволяют достичь полной скорости работы функциональных устройств. Некоторые ограничения микроархитектуры преодолены в процессорах P-M и P-M2 (Core Duo).