Параллельные вычислительные системы (Лекция)
ПЛАН ЛЕКЦИИ
– Виды параллелизма
– Реализация параллельных систем
– Нейровычислительные системы
– Сложности использования параллельных систем
– Программирование параллельных систем
Виды параллелизма
Параллельная обработка данных имеет две разновидности: конвейерность и собственно параллельность.
Параллельная обработка. Если некое устройство выполняет одну операцию за единицу времени, то
тысячу операций оно выполнит за тысячу единиц. Если предположить, что есть пять таких же независимых устройств, способных работать
одновременно, то ту же тысячу операций система из пяти устройств может
выполнить уже не за тысячу, а за двести единиц времени.
Конвейерная обработка. Что необходимо для сложения двух вещественных чисел, представленных в
форме с плавающей запятой? Целое множество мелких операций таких, как сравнение
порядков, выравнивание порядков, сложение мантисс, нормализация и т.п.
Процессоры первых компьютеров выполняли все эти "микрооперации" для
каждой пары аргументов последовательно одна за одной
до тех пор, пока не доходили до окончательного результата, и лишь после этого
переходили к обработке следующей пары слагаемых. Идея конвейерной обработки
заключается в выделении отдельных этапов выполнения общей операции, причем
каждый этап, выполнив свою работу, передавал бы результат следующему,
одновременно принимая новую порцию входных данных. Получается очевидный выигрыш
в скорости обработки за счет совмещения прежде разнесенных во времени операций.
Предположим, что в операции можно выделить пять микроопераций, каждая из
которых выполняется за одну единицу времени. Если есть одно неделимое
последовательное устройство, то 100 пар аргументов оно обработает за 500
единиц. Если каждую микрооперацию выделить в отдельный этап (или иначе говорят–
ступень) конвейерного устройства, то на пятой единице времени на разной стадии
обработки такого устройства будут находится первые
пять пар аргументов, а весь набор из ста пар будет обработан за 5 + 99 = 104
единицы времени – ускорение по сравнению с последовательным устройством почти в
пять раз (по числу ступеней конвейера).
Казалось бы, конвейерную обработку можно с успехом заменить обычным
параллелизмом, для чего продублировать основное устройство столько раз, сколько
ступеней конвейера предполагается выделить. Но, увеличив в
пять раз число устройств, мы значительно увеличиваем как объем
аппаратуры, так и ее стоимость.
Реализация параллельных систем
Производительность компьютеров росла экспоненциально, начиная с 1945
года и до настоящего момента (если брать средний показатель за каждые 10 лет).
Компьютерная архитектура претерпела значительные изменения, пройдя путь от последовательной до параллельной.
Производительность компьютера непосредственно
зависит от времени, требующегося на выполнение основных функций и количество
этих основных операций, которые могут быть выполнены одновременно. Время
выполнения одной простейшей инструкции в конечном итоге ограничено.
Несложно сделать вывод, что нельзя
ограничиваться увеличением скорости лишь за счет тактовой частоты процессоров.
Зависимость от процессоров в конечном итоге заводит в тупик. Другая стратегия в
этой области – использование внутреннего параллелизма в чипе процессора. Но
такая технология очень дорога. Современные суперкомпьютеры основываются в
большей степени на идее использование большого количества относительно не
дорогих уже имеющихся процессоров.
Это подразумевает и такие системы, как:
суперкомпьютеры, оборудованные тысячами процессоров; сети рабочих станций;
мультипроцессорные рабочие станции и т.д.
Мультикомпьютер – это некоторое количество машин фон Неймана (узлов) связанных
между собой сетью. Каждый компьютер выполняет свою программу. Эти программы
могут иметь доступ к локальной памяти и умеют посылать и получать сообщения
через сеть. Сообщения, используемые для связи между компьютерами, эквивалентны
операциям чтения или записи с удаленной памятью. В идеализированной сети время
доставки сообщения между машинами не зависит от расстояния между узлами или
сетевого трафика, но зависит от длины отправляемого письма.
Определяющий параметр модели мультикомпьютера
– это то, что доступ к локальной (в том же узле) памяти менее дорог, чем
доступы к удаленной (находящейся в другом узле) памяти. Т.е. операции чтения и
записи менее дороги, чем отправление или получение сообщений. Следовательно,
желательно, чтобы обращение к локальным данным было гораздо более частым, чем к
удаленным данным. Это фундаментальное свойство программного обеспечения
называется локальностью. Значение локальности зависит от отношения стоимости
дистанционного доступа к локальному.
Другие модели машин. Рассмотрим важнейшие компьютерные архитектуры. Мультикомпьютер
очень похож на то, что часто называют компьютером с
распределенной памятью MIMD (Multiple Instruction Multiple Data). MIMD означает, что каждый процессор может обрабатывать отдельный
поток инструкций над его собственными локальными данными. Распределенная память
означает, что память распределена между процессорами. Принципиальным отличием
MIMD компьютера от мультикомпьютера – это то, что
стоимость доставки сообщения между двумя узлами не зависит от местоположения
узла и сетевого трафика. Основные представители этого класса: IBM SP, Intel Paragon, Thinking Machines CM5,
Cray T3D,
Meiko CS-2, и CUBE.
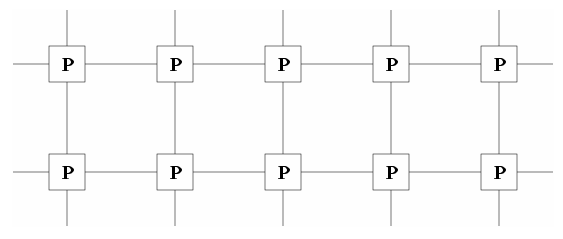
Рис. MIMD компьютер с распределенной памятью
с сеточным
Другой класс суперкомпьютеров – мультипроцессор или MIMD компьютер с
разделяемой памятью. В мультипроцессоре все процессоры делят доступ к общей
памяти, обычно через шину или через иерархию шин. В идеализированной модели
параллельной машины с произвольным доступом (PRAM) часто используют
теоретически изучаемые параллельные алгоритмы, любой процессор может получить
доступ к любому элементу памяти в одно и то же время. Такая архитектура обычно
подразумевает некоторые специальные формы устройства памяти. Количество
обращений к разделяемой памяти уменьшается за счет хранения копий часто
используемых данных в кэше, связанном с каждым
процессором.
Доступ к этому кэшу намного быстрее, чем
доступ к разделяемой памяти, следовательно, локальность очень важна. Программы,
разработанные для мультикомпьютеров, могут так же
эффективно работать на мультипроцессорах, потому что разделяемая память
позволяет эффективную реализацию передачи сообщений. Представители этого класса
– Silicon Graphics Challenge, Sequent Symmetry и многие мультипроцессорные рабочие станции.
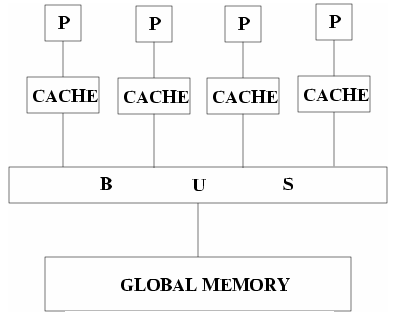
Рис. Мультипроцессор с разделяемой
памятью
Более специализированный класс параллельных компьютеров – это SIMD (Single Instruction Miltiple Data) компьютеры. В SIMD машинах все процессоры
оперируют с одним и тем же потоком инструкций над различными порциями данных.
Этот подход может уменьшить сложность программного и аппаратного обеспечения,
но это имеет смысл только для специализированных проблем, характеризуемых
высокой степенью закономерности, например обработка изображений и определенные
виды цифрового моделирования. Алгоритмы, применимые на мультикомпьютерах,
не могут в общих чертах эффективно выполняться в SIMD компьютерах.
Нейровычислительные системы
Нейровычислительное устройство – это система, функционирование
которой в максимальной степени ориентировано на реализацию нейросетевых
алгоритмов. Основное отличие нейрокомпьютеров от других вычислительных систем –
это обеспечение высокого параллелизма вычислений за счет применения
специализированного нейросетевого логического базиса
или конкретных архитектурных решений. Использование возможности представления нейросетевых алгоритмов для реализации на нейросетевом логическом базисе является основной предпосылкой
резкого увеличения производительности нейрокомпьютеров.
Сейчас разработки цифровых нейрокомпьютеров наиболее активно ведутся по
следующим направлениям:
·
программная эмуляция нейросетевых
алгоритмов на основе использования обычных вычислительных средств и ППО по
моделированию нейросетей;
·
программно-аппаратная эмуляция
нейросетей на основе стандартных вычислительных
средств с подключаемым виртуальным нейросетевым
блоком, выполняющим основные нейрооперации, и ППО,
осуществляющим функции общего управления;
·
аппаратная реализация нейронных сетей.
Несмотря на то, что наибольшего эффекта при реализации нейросетевых алгоритмов удается добиться лишь с
использованием нейрокомпьютеров третьего направления, их широкое применение
ограничивается высокой. Например, нейрокомпьютер Synaps1 – один из
представителей нейрокомпьютеров третьего направления, имеет мультипроцессорную
архитектуру, оригинальное построение подсистемы памяти, а для выполнения
вычислительных операций использует сигнальные процессоры и специальные сигнальные
матричные процессоры МА16. За счет этого производительность нейрокомпьютера
составила порядка несколько миллиардов умножений и сложений в секунду.
Программное обеспечение данной системы включает в себя ОС Synaps1 с библиотекой
нейроалгоритмов, а также ППО: базовую библиотеку НС,
компилятор языка программирования нейроалгоритмов (nAPL) (набор библиотечных функций для С++)
и т.п. Прикладные исследования показали, что использование нейрокомпьютеров
третьего направления позволяет повысить производительность обычных
вычислительных систем как минимум на три порядка и моделировать НС с миллионами соединений. Так, например, Synaps1 позволяет
моделировать нейросеть с 64 миллионами синапсов с
использованием различных активационных функций.
Два класса компьютерных систем, которые
иногда используют как параллельные компьютеры – это локальная сеть (LAN), в
которой компьютеры, находящиеся в физической близости (например, то же
строение), связываются быстрой сетью, и глобальная сеть (WAN), в которой
соединены географически удаленные компьютеры. Хотя системы такого типа доставляют
дополнительные проблемы, такие как безопасность, надежность, они могут быть
рассмотрены для различных целей как мультикомпьютеры,
хотя и с высокой стоимостью удаленного доступа.
Сложности
использования параллельных систем
Гигантская производительность параллельных компьютеров и супер-ЭВМ с
лихвой компенсируется сложностями их использования.
У вас есть программа и доступ, скажем, к 256-процессорному компьютеру.
Что вы ожидаете? Да ясно что: вы вполне законно ожидаете, что программа будет
выполняться в 256 раз быстрее, чем на одном процессоре. А вот как раз этого,
скорее всего, и не будет.
Закон Амдала.
Предположим, что в программе доля операций, которые нужно выполнять
последовательно, равна f, где 0<=f<=1 (при этом доля понимается не по статическому
числу строк кода, а по числу операций в процессе выполнения). Крайние случаи в
значениях f соответствуют полностью параллельным (f = 0) и полностью последовательным (f = 1) программам. Тогда для того, чтобы оценить,
какое ускорение S может быть получено на компьютере из 'p'
процессоров при данном значении f, можно
воспользоваться законом Амдала: если 9/10 программы исполняется параллельно, а
1/10 по-прежнему последовательно, то ускорения более,
чем в 10 раз получить в принципе невозможно вне зависимости от качества
реализации параллельной части кода и числа используемых процессоров (10 получается
только в том случае, когда время исполнения параллельной части равно 0).
Следствие закона Амдала. Для того, чтобы ускорить выполнение программы
в q раз, необходимо ускорить не менее, чем в q раз не менее, чем (1-1/q) -ю часть
программы. Следовательно, если есть желание ускорить программу в 100 раз по
сравнению с ее последовательным вариантом, то необходимо получить не меньшее
ускорение не менее, чем для 99.99% кода!
Таким образом, заставить параллельную вычислительную систему работать с
максимальной эффективностью на конкретной программе это задача не из простых,
поскольку необходимо тщательное согласование структуры программ и алгоритмов с
особенностями архитектуры параллельных вычислительных систем.
Программирование параллельных систем
Модель машины фон Неймана предполагает, что процессор выполняет
последовательность инструкций. Инструкции могут определять в дополнение к
различным арифметическим операциям адреса данных, которые надо прочитать/записать
в памяти, и/или адрес следующей инструкции, которую надо выполнить. Пока
возможно только программировать компьютер с точки зрения этой основной модели,
этот метод для большинства целей недопустимо сложен из-за того, что мы должны
следить за миллионами позиций памяти и организовать выполнение тысяч машинных
инструкций. Следовательно, прикладывается модульная техника разработки,
посредством которой сложные программы создаются из простых компонент, и
компоненты структуры с точки зрения абстракций более высокого уровня (такие,
как структуры данных, итерационные циклы и процедуры). Абстракции (например,
процедуры) делают эксплуатацию модульности легче, допуская объекты, которыми
должны управлять без беспокойства для их внутренней структуры. Так сделаны высокоуровневые
языки, как, например, Fortran, C, Ada
и Java, которые допускают
разработку, выраженную с точки зрения этих абстракций, которые переводятся
автоматически в выполняемый код. Параллельное программирование вводит
дополнительные источники сложности: если мы должны запрограммировать на самом
низком уровне, нам нужно не только увеличить количество выполняемых инструкций,
но также управлять выполнением тысяч процессоров и координированием миллионов
межпроцессорных взаимодействий. Следовательно, абстракция и модульность
по крайней мере так же важны, как и в последовательном программировании.
Фактически, мы выделим модульность как четвертое фундаментальное требование для
параллельного программного обеспечения, дополнительно к параллелизму, масштабируемости, и локальности.
Основные абстракции, используемые в параллельном
программиро-вании, сводятся к задачам и каналам:
1.
Параллельное вычисление состоит из одной или
более задач. Задачи выполняются параллельно. Количество задач может меняться во
время выполнения программы.
2.
Задача изолирует последовательную программу и
локальную память. Вдобавок набор вводов и выводов определяет свой интерфейс в
своей среде.
3.
Задача может выполнять четыре основных действия
дополнительно к чтению и записи в локальной памяти: послать сообщение на свои
порты вывода, получить сообщение со своих портов ввода, создать новые задачи и
уничтожить (завершить) задачу.
4.
Операция отправления сообщения – асинхронная,
она завершается немедленно. Операция получения – синхронная, она вызывает
выполнение задачи, блокируя процесс, пока сообщение не будет получено.
5.
Пары ввода/вывода могут связываться сообщениями
в очереди, называемыми каналами. Каналы могут создаваться и удаляться, и ссылки
на каналы (порты) способны включаться в сообщения, так что связность изменяется
динамически.
6.
Задания могут отображаться в физических
процессорах различными способами; отображающее применение не влияет на
семантику программы. Конкретно многочисленные задания могут отображаться в
единственном процессоре (можно также представить, что единичная задача может
быть отображенной в множестве процессоров, но эта
возможность здесь не учитывается.)
Абстракция задач требует свойство локальности: данные, содержащиеся в
локальной памяти задачи – «закрытые»; другие данные – «удаленные». Канальная
абстракция обеспечивает механизм для указания, вычисление каких данных из одной
задачи требуется для начала работы другой задачи. (Это охарактеризовано
зависимостью данных). Модель задач и каналов обладает и некоторыми другими свойствами:
Производительность.
Последовательные абстракции программирования, такие как, например, процедуры и
структуры данных, эффективны из-за того, что они могут быть отображены просто и
эффективно в компьютере фон Неймана. Задачи и каналы имеют аналогично прямое
распределение в мультикомпьютере. Задача представляет
часть кода, который может быть выполнен последовательно в единственном
процессоре. Если две задачи, которые делят канал, отображаются в других
процессорах, канальное соединение осуществлено как межпроцессорное соединение;
если они отображаются в том же процессоре, могут быть использованы некоторые
более эффективные механизмы.
Независимость распределения. Поскольку задания взаимодействуют, используя тот же механизм (каналы)
независимо от положения задачи, результат вычисленный
программой не зависит от того, где задача выполняется. Следовательно, алгоритмы
могут разрабатываться и осуществляться без беспокойства о количестве
процессоров, на которых они будут выполняться; фактически, алгоритмы часто разрабатываются
так, что создают гораздо больше задач, чем процессоров. Это простой путь
достижения масштабности: когда количество процессоров увеличивается, количество
задач на процессор уменьшается, но сам алгоритм не должен быть модифицирован.
Когда имеется большее число задач, чем процессоры смогли бы обслуживать, чтобы
замаскировать задержки связи, обеспечиваются другие вычисления, которые могут
выполняться, пока выполняется связь для доступа к удаленным данным.
Модульность. В
модульном составлении программы различные компоненты программ разрабатываются
отдельно как независимые модули и затем объединяются, чтобы получить полную
программу. Взаимодействие между модулями ограничивается отчетливо выраженными
интерфейсами. Следовательно, модульные реализации могут быть изменены без
модификации других компонент, и свойства программы могут определяться из
спецификации ее модулей и кода, который соединяет эти модули вместе. Когда
успешно приложена модульная разработка, уменьшается программная сложность и
облегчается многократное использование кода.
Детерминизм.
Алгоритм или программа детерминированы, если при
выполнении с конкретным вводом всегда получается один и тот же вывод. Он
недетерминирован, если многочисленные выполнения с тем же вводом могут дать
другой вывод. Хотя недетерминизм иногда полезен и должен поддерживаться,
параллельная модель программирования, которая облегчает написание
детерминированных программ, очень желательна. Детерминированные программы имеют
тенденцию быть более понятными. Также при проверке на правильность должна
вычисляться только одна последовательность выполнения параллельной программы, а
не все возможные для выполнения.